This article aims at exploiting GPGPU (GP2U) computation capabilities to improve physical and scientific simulations. In order for the reader to understand all the passages, we will gradually proceed in the explanation of a simple physical simulation based on the well-known Wave equation. A classic CPU implementation will be developed and eventually another version using GPU workloads is going to be presented.
PDE stands for “Partial differential equation” and indicates an equation which has one or more partial derivatives as independent variables in its terms. The order of the PDE is usually defined as the highest partial derivative in it. The following is a second-order PDE:
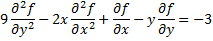
Usually a PDE of order n having m variables xi for i=1,2…m is expressed as

A compact form to express  is ux and the same applies to
is ux and the same applies to  (uxx ) and (uxy ).
(uxx ) and (uxy ).
The wave equation is a second order partial differential equation used to describe water waves, light waves, sound waves, etc. It is a fundamental equation in fields such as electro-magnetics, fluid dynamics and acoustics. Its applications involve modeling the vibration of a string or the air flow dynamics as a result from an aircraft movement.
We can derive the one-dimensional wave equation (i.e. the vibration of a string) by considering a flexible elastic string that is tightly bound between two fixed end-points lying of the x axis

A guitar string has a restoring force that is proportional to how much it’s stretched. Suppose that, neglecting gravity, we apply a y-direction displacement at the string (i.e. we’re slightly pulling it). Let’s consider only a short segment of it between x and x+ :
:

Let’s write down  for the small red segment in the diagram above. We assume that the string has a linear density
for the small red segment in the diagram above. We assume that the string has a linear density  (linear density is a measure of mass per unit of length and is often used with one-dimensional objects). Recalling that if a one-dimensional object is made of a homogeneous substance of length L and total mass m the linear density is
(linear density is a measure of mass per unit of length and is often used with one-dimensional objects). Recalling that if a one-dimensional object is made of a homogeneous substance of length L and total mass m the linear density is

we have m= .
The forces (as already stated we neglect gravity as well as air resistance and other tiny forces) are the tensions T at the ends. Since the string is actually waving, we can’t assume that the two T vectors cancel themselves: this is the  force we are looking for. Now let’s make some assumptions to simplify things: first we consider the net force we are searching for as vertical (actually it’s not exactly vertical but very close)
force we are looking for. Now let’s make some assumptions to simplify things: first we consider the net force we are searching for as vertical (actually it’s not exactly vertical but very close)

Furthermore we consider the wave amplitude small. That is, the vertical component of the tension  at the x+ end of the small segment of string is
at the x+ end of the small segment of string is 

The slope is  if we consider dx and dy as the horizontal and vertical components of the above image. Since we have considered the wave amplitude to be very tiny, we can therefore assume
if we consider dx and dy as the horizontal and vertical components of the above image. Since we have considered the wave amplitude to be very tiny, we can therefore assume  . This greatly helps us:
. This greatly helps us:  and the total vertical force from the tensions at the two ends becomes
and the total vertical force from the tensions at the two ends becomes

The equality becomes exact in the limit  .
.
We see that y is a function of x, but it is however a function of t as well: y=y(x,t). The standard convention for denoting differentiation with respect to one variable while the other is held constant (we’re looking at the sum of forces at one instant of time) let us write

The final part is to use Newton’s second law and put everything together: the sum of all forces, the mass (substituted with the linear density multiplied by the segment length) and the acceleration (i.e. just  because we’re only moving in the vertical direction, remember the small amplitude approximation).
because we’re only moving in the vertical direction, remember the small amplitude approximation).


And we’re finally there: the wave equation. Using the spatial Laplacian operator, indicating the y function (depending on x and t) as u and substituting  (a fixed constant) we have the common compact form
(a fixed constant) we have the common compact form

The two-dimensional wave equation is obtained by adding a second spatial term to the equation as follows

The constant c has dimensions of distance per unit time and thus represents a velocity. We won’t prove here that c is actually the velocity at which waves propagate along a string or through a surface (although it’s surely worth noting). This makes sense since the wave speed increases with tension experienced by the medium and decreases with the density of the medium.
In a physical simulation we need to take into account forces other than just the surface tension: the average amplitude of the waves on the surface diminishes in real-world fluids. We may therefore add a viscous damping force to the equation by introducing a force that acts in the opposite direction of the velocity of a point on the surface:

where the nonnegative constant  represents the viscosity of the fluid (it controls how long it takes for the wave on the surface to calm down, a small allows waves to exist for a long time as with water while a large causes them to diminish rapidly as for thick oil).
represents the viscosity of the fluid (it controls how long it takes for the wave on the surface to calm down, a small allows waves to exist for a long time as with water while a large causes them to diminish rapidly as for thick oil).
To actually implement a physical simulation which uses the wave PDE we need to find a method to solve it. Let’s solve the last equation we wrote with the damping force
here t is the time, x and y are the spatial coordinates of the 2D wave, c2 is the wave speed and the damping factor. u=u(t,x,y) is the function we need to calculate: generally speaking it could represent various effects like a change of height of a pool’s water, electric potential in an electromagnetic wave, etc..
A common method to solve this problem is to use the finite difference method. The idea behind is basically to replace derivatives with finite differences which can be easily calculated in a discrete algorithm. If there is a function f=f(x) and we want to calculate its derivative respect to the x variable we can write

if h is a discrete small value (which is not zero), then we can approximate the derivative with

the error of such an approach could be derived from Taylor’s theorem but that isn’t the purpose of this paper.
A finite difference approach uses one of the following three approximations to express the derivative


Let’s stick with the latter (i.e. central difference); this kind of approach can be generalized, so if we want to calculate the discrete version of f''(x) we could first write
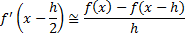

and then calculate f''(x) as follows



The same idea is used to estimate the partial derivatives below

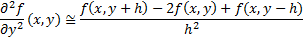
Let’s get back to the wave equation. We had the following
let’s apply the partial derivative formula just obtained to it (remember that u=u(t,x,y), that is, u depends by t,x and y)

This is quite a long expression. We just substituted the second derivatives and the first derivatives with the formulas we got before.
If we now consider  , we are basically forcing the intervals where the derivatives are calculated to be the same for both the x and the y directions (and we can greatly simplify the expression):
, we are basically forcing the intervals where the derivatives are calculated to be the same for both the x and the y directions (and we can greatly simplify the expression):

To improve the readability, let us substitute some of the terms with letters



and we have

If you look at the t variables we have something like

This tells us that the new wave’s height (at t+1) will be the current wave height (t) plus the previous wave height (t-1) plus something in the present (at t) depending only by what are the values around the wave point we are considering.
This can be visualized as a sequence of time frames one by another where a point on the surface we are considering evolves

The object

has a central dot which represents a point (t,x,y) on the surface at time t. Since the term we previously called something_at_t(x,y) is actually

the value of the central point is influenced by five terms and the latter is its same value (-4ut,x,y ) multiplied by -4.
As we stated before, the wave PDE can be effectively solved with finite difference methods. However we still need to write some resolution code before a real physical simulation can be set up. In the last paragraph we eventually ended up obtaining
we then simplified this expression with
This is indeed a recursive form which may be modeled with the following pseudo-code
for each t in time
{
ut+1 <- ut+ut-1+something_at_t(x,y)
// Do something with the new ut+1, e.g. you can draw the wave here
ut-1<- ut
ut <- ut+1
}
The above pseudo-code is supposed to run in retained-mode so the application might be able to draw the wave in each point of the surface we’re considering by simply calling draw_wave(ut+1) .
Let assume that we’re modeling how a water wave evolves and so let the u function represent the wave height (0 – horizontal level): we can now write down the beginning of our pseudo-code
// Surface data
height = 500;
width = 500;
// Wave parameters
c = 1; // Speed of wave
dx = 1; // Space step
dt = 0.05; // Time step
k=0.002 // Decay factor
kdt=k*dt; // Decayment factor per timestep, recall that q = 2 - kdt, r = -1 +kdt
c1 = dt^2*c^2/dx^2; // b factor
// Initial conditions
u_current_t = zeros(height,width); // Create a height x width zero matrix
u_previous_t = u_current_t;
We basically defined a surface where the wave evolution will be drawn (a 500x500 area) and initialized the wave parameters we saw a few paragraphs ago (make sure to recall the q,r and b substitutions we did before). The initial condition is a zero matrix (u_current_t) so the entire surface is quiet and there’s no wave evolving.
Given that we are considering a matrix surface (every point located at (x;y) coordinates is described by a u value indicating the height of the wave there) we need to write code to implement the
line in the for cycle. Actually the above expression is a simplified form for
and we need to implement this last one. We may write down something like the following
for(t=0; t<A_LOT_OF_TIME; t += dt)
{
u_next_t = (2-kdt)*u_current_t+(kdt-1)*u_previous_t+c1*something_at_t(x,y)
u_previous_t = u_current_t; // Current becomes old
u_current_t = u_next_t; // New becomes current
// Draw the wave
draw_wave(u_current_t)
}
that is, a for cycle with index variable t increasing by dt at every step. Everything should be familiar by now because the (2-kdt),(kdt-1) and c1 terms are the usual q,r and b substitutions. Last thing we need to implement is the something_at_t(x,y) term, as known as:
The wave PDE we started from was
and the term we are interested now is this:

that, in our case, is
Since we have a matrix of points representing our surface, we are totally in the discrete field, and since we need to perform a second derivative on a matrix of discrete points our problem is the same as having an image with pixel intensity values I(x,y) and need to calculate its Laplacian
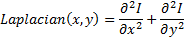
This is a common image processing task and it’s usually solved by applying a convolution filter to the image we are interested in (in our case: the matrix representing the surface). A common small kernel used to approximate the second derivatives in the definition of the Laplacian is the following

So in order to implement the
term, we need to apply the D Laplacian kernel as a filter to our image (i.e. the u_current_t):
u_next_t=(2-kdt)*u_current_t+(kdt-1)*u_previous_t+c1* convolution(u_current_t,D);
In fact in the element we saw earlier

the red dot elements are weighted and calculated with a 2D convolution of the D kernel.
An important element to keep in mind while performing the D kernel convolution with our u_current_t matrix is that every value in outside halos (every value involved in the convolution but outside the u_current_t matrix boundaries) should be zero as in the image below
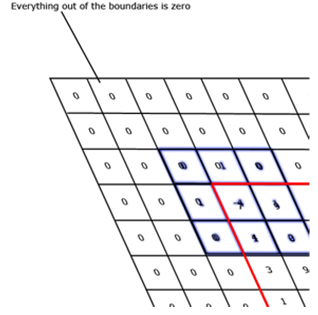
In the picture above the red border is the u_current_t matrix perimeter while the blue 3x3 matrix is the D Laplacian kernel, everything outside the red border is zero. This is important because we want our surface to act like water contained in a recipient and the waves in the water to “bounce back” if they hit the container’s border. By zeroing all the values outside the surface matrix we don’t receive wave contributions from the outside of our perimeter nor do we influence in any way what’s beyond it. In addition the “energy” of the wave doesn’t spread out and is partially “bounced back” by the equation.
Now the algorithm is almost complete: our PDE assures us that every wave crest in our surface will be properly “transmitted” as a real wave. The only problem is: starting with a zero-everywhere matrix and letting it evolve would produce just nothing. Forever.
We will now add a small droplet to our surface to perturb it and set the wheels in motion.
To simulate as realistic as possible the effect of a droplet falling into our surface we will introduce a “packet” in our surface matrix. That means we are going to add a matrix that represents a discrete Gaussian function (similar to a Gaussian kernel) to our surface matrix. Notice that we’re going to “add”, not to “convolve”.
Given the 2D Gaussian formula

we have that A is the Gaussian amplitude (so will be our droplet amplitude), x0 and y0 are the center’s coordinates and the  and
and  are the spreads of the blob. Putting a negative amplitude like in the following image we can simulate a droplet just fallen into our surface.
are the spreads of the blob. Putting a negative amplitude like in the following image we can simulate a droplet just fallen into our surface.
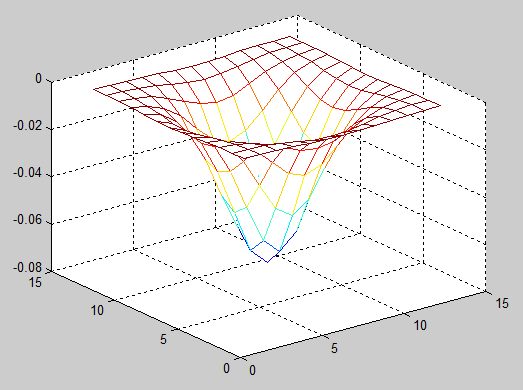
To generate the droplet matrix we can use the following pseudo-code
// Generate a droplet matrix
dsz = 3; // Droplet size
da=0.07; // Droplet amplitude
[X,Y] = generate_XY_planes(dsz,da);
DropletMatrix = -da * exp( -(X/dsz)^2 -(Y/dsz)^2);
da is the droplet amplitude (and it’s negative as we just said), while dsz is the droplet size, that is, the Gaussian “bell” radius. X and Y are two matrices representing the X and Y plane discrete values

so the X and Y matrices for the image above are

And the final DropletMatrix is similar to the following
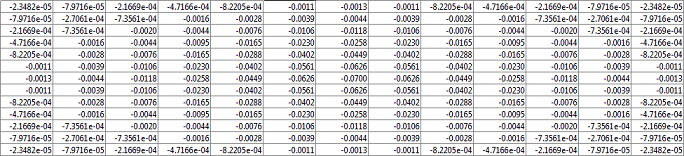
where the central value is -0.0700. If you drew the above matrix you would obtain a 3D Gaussian function which can now model our droplet.
The final pseudo-code for our wave algorithm is the following
// Surface data
height = 500;
width = 500;
// Wave parameters
c = 1; // Speed of wave
dx = 1; // Space step
dt = 0.05; // Time step
k=0.002 // Decay factor
kdt=k*dt; // Decayment factor per timestep, recall that q = 2 - kdt, r = -1 +kdt
c1 = dt^2*c^2/dx^2; // b factor
// Initial conditions
u_current_t=zeros(height,width); // Create a height x width zero matrix
u_previous_t = u_current_t;
// Generate a droplet matrix
dsz = 3; // Droplet size
da=0.07; // Droplet amplitude
[X,Y] = generate_XY_planes(dsz,da);
DropletMatrix = -da * exp( -(X/dsz)^2 -(Y/dsz)^2);
// This variable is used to add just one droplet
One_single_droplet_added = 0;
for(t=0; t<A_LOT_OF_TIME; t = t + dt)
{
u_next_t = (2-kdt)*u_current_t+(kdt-1)*u_previous_t+c1*convolution(u_current_t,D);
u_previous_t = u_current_t; // Current becomes old
u_current_t = u_next_t; // New becomes current
// Draw the wave
draw_wave(u_current_t)
if(One_single_droplet_added == 0)
{
One_single_droplet_added = 1; // no more droplets
addMatrix(u_current_t, DropletMatrix, [+100;+100]);
}
}
The variable One_single_droplet_added is used to check if the droplet has already been inserted (we want just one droplet). The addMatrix function adds the DropletMatrix values to the u_current_t surface matrix values centering the DropletMatrix at the point (100;100), remember that the DropletMatrix is smaller (or equal) to the surface matrix, so we just add the DropletMatrix’s values to the u_current_t’s values that fall within the dimensions of the DropletMatrix.
Now the algorithm is complete, although it is still a theoretical simulation. We will soon implement it with real code.
We will now discuss how the above algorithm has been implemented in a real C++ project to create a fully functional openGL physical simulation.
The sequence diagram below shows the skeleton of the program which basically consists of three main parts: the main module where the startup function resides as well as the kernel function which creates the matrix image for the entire window, an openGL renderer wrapper to encapsulate GLUT library functions and callback handlers and a matrix hand-written class to simplify matrix data access and manipulation. Although a sequence diagram would require following a standard software engineering methodology and its use is strictly enforced by predetermined rules, nonetheless we will use it as an abstraction to model the program’s control flow

The program starts at the main() and creates an openGLrenderer object which will handle all the graphic communication with the GLUT library and the callback events (like mouse movements, keyboard press events, etc.). OpenGL doesn’t provide routines for interfacing with a windowing system, so in this project we will rely on GLUT libraries which provide a platform-independent interface to manage windows and input events. To create an animation that runs as fast as possible we will set an idle callback with the glutIdleFunc() function. We will explain more about this later.
Initially the algorithm sets its initialization variables (time step, space step, droplet amplitude, Laplacian 2D kernel, etc.. practically everything we saw in the theory section) and every matrix corresponding to the image to be rendered is zeroed out. The Gaussian matrix corresponding to the droplets is also preprocessed. A structure defined in openGLRenderer’s header file contains all the data which should be retained across image renderings
 Collapse | Copy Code
Collapse | Copy Code typedef struct kernelData
{
float a1; float a2; float c1; sMatrix* u;
sMatrix* u0;
sMatrix* D;
int Ddim; int dsz; sMatrix* Zd;
} kernelData;
The structure is updated each time a time step is performed since it contains both current and previous matrices that describe the waves evolution across time. Since this structure is both used by the openGL renderer and the main module to initialize it, the variable is declared as external and defined afterwards in the openGLrenderer cpp file (so its scope goes beyond the single translation unit). After everything has been set up the openGLRenderer class’ startRendering() method is called and the openGL main loop starts fetching events. The core of the algorithm we saw is in the main module’s kernel() function which is called every time an openGL idle event is dispatched (that is, the screen is updated and the changes will be shown only when the idle callback has completed, thus the amount of rendering work here performed should be minimized to avoid performance loss).
The kernel’s function code is the following
Collapse | Copy Code void kernel(unsigned char *ptr, kernelData& data)
{
sMatrix un(DIM,DIM);
un = (*data.u)*data.a1 + (*data.u0)*data.a2 + convolutionCPU((*data.u),(*data.D))*data.c1;
(*data.u0) = (*data.u);
(*data.u) = un;
matrix2Bitmap( (*data.u), ptr );
if(first_droplet == 1) {
first_droplet = 0;
int x0d= DIM / 2; int y0d= DIM / 2;
for(int Zdi=0; Zdi < data.Ddim; Zdi++)
{
for(int Zdj=0; Zdj < data.Ddim; Zdj++)
{
(*data.u)(y0d-2*data.dsz+Zdi,x0d-2*data.dsz+Zdj) += (*data.Zd)(Zdi, Zdj);
}
}
}
m_renderer->renderWaitingDroplets();
}
The pattern we followed in the wave PDE evolution can be easily recognized in the computational-intensive code line
un = (*data.u)*data.a1 + (*data.u0)*data.a2 + convolutionCPU((*data.u),(*data.D))*data.c1;
which basically performs the well-known iterative step
All constants are preprocessed to improve performances.
It is to be noticed that the line adds up large matrices which are referred in the code as sMatrix objects. The sMatrix class is an handwritten simple class that exposes simple operator overrides to ease working with matrices. Except that one should bear in mind that large matrix operations shall avoid passing arguments by value and that to create a new matrix and copy it to the destination a copy constructor is required (to avoid obtaining a shallow copy without the actual data), the code is pretty straight forwarding so no more words will be spent on it
Collapse | Copy Code class sMatrix
{
public:
int rows, columns;
float *values;
sMatrix(int height, int width)
{
if (height == 0 || width == 0)
throw "Matrix constructor has 0 size";
rows = height;
columns = width;
values = new float[rows*columns];
}
sMatrix(const sMatrix& mt)
{
this->rows = mt.rows;
this->columns = mt.columns;
this->values = new float[rows*columns];
memcpy(this->values, mt.values, this->rows*this->columns*sizeof(float));
}
~sMatrix()
{
delete [] values;
}
sMatrix& operator= (sMatrix const& m)
{
if(m.rows != this->rows || m.columns != this->columns)
{
throw "Size mismatch";
}
memcpy(this->values,m.values,this->rows*this->columns*sizeof(float));
return *this; }
float& operator() (const int row, const int column)
{
if (row < 0 || column < 0 || row > this->rows || column > this->columns)
throw "Size mismatch";
return values[row*columns+column]; }
sMatrix operator* (const float scalar)
{
sMatrix result(this->rows, this->columns);
for(int i=0; i<rows*columns; i++)
{
result.values[i] = this->values[i]*scalar;
}
return result; }
sMatrix operator+ (const sMatrix& mt)
{
if (this->rows != mt.rows || this->columns != mt.columns)
throw "Size mismatch";
sMatrix result(this->rows, this->columns);
for(int i=0; i<rows; i++)
{
for(int j=0; j<columns; j++)
result.values[i*columns+j] = this->values[i*columns+j] + mt.values[i*columns+j];
}
return result; }
};
The convolution is performed with the following code (a classic approach):
Collapse | Copy Code sMatrix convolutionCPU(sMatrix& A, sMatrix& B)
{
sMatrix result(A.rows, A.columns);
int kernelHradius = (B.rows - 1) / 2;
int kernelWradius = (B.columns - 1) / 2;
float convSum, convProd, Avalue;
for(int i=0; i<A.rows; i++)
{
for(int j=0; j<A.columns; j++)
{
convSum = 0;
for(int bi=0; bi<B.rows; bi++)
{
for(int bj=0; bj<B.columns; bj++)
{
int relpointI = i-kernelHradius+bi;
int relpointJ = j-kernelWradius+bj;
if(relpointI < 0 || relpointJ < 0 || relpointI >= A.rows || relpointJ >= A.columns)
Avalue = 0;
else
Avalue = A(i-kernelHradius+bi,j-kernelWradius+bj);
convProd = Avalue*B(bi,bj);
convSum += convProd;
}
}
result(i,j) = convSum;
}
}
return result;
}
After calculating the system’s evolution, the time elapsing is simulated by swapping the new matrix with the old one and discarding the previous state as we described before.
Then a matrix2Bitmap() call performs a matrix-to-bitmap conversion as its name suggests, more precisely the entire simulation area is described by a large sMatrix object which contains, obviously, float values. To actually render these values as pixel units we need to convert each value to its corresponding RGBA value and pass it to the openGLRenderer class (which in turn will pass the entire bitmap buffer to the GLUT library). In brief: we need to perform a float-to-RGBcolor mapping.
Since in the physical simulation we assumed that the resting water height is at 0 and every perturbation would heighten or lower this value (in particular the droplet Gaussian matrix lowers it by a maximum -0.07 factor), we are searching for a [-1;1] to color mapping. A HSV color model would better simulate a gradual color transition as we actually experience with our own eyes, but this would require converting it back to RGB values to set up a bitmap map to pass back at the GLUT wrapper. For performance reasons we chose to assign each value a color (colormap). A first solution would have been implementing a full [-1;1] -> [0x0;0xFFFFFF] mapping in order to cover all the possible colors in the RGB format
Collapse | Copy Code RGB getColorFromValue(float value)
{
RGB result;
if(value <= -1.0f)
{
result.r = 0x00;
result.g = 0x00;
result.b = 0x00;
}
else if(value >= 1.0f)
{
result.r = 0xFF;
result.g = 0xFF;
result.b = 0xFF;
}
else
{
float step = 2.0f/0xFFFFFF;
unsigned int cvalue = (unsigned int)((value + 1.0f)/step);
if(cvalue < 0)
cvalue = 0;
else if(cvalue > 0xFFFFFF)
cvalue = 0xFFFFFF;
result.r = cvalue & 0xFF;
result.g = (cvalue & 0xFF00) >> 8;
result.b = (cvalue & 0xFF0000) >> 16;
}
return result;
}
However the above method is either performance-intensive and doesn’t render very good a smooth color transition: let’s take a look at a droplet mapped like that

looks more like a fractal rather than a droplet, so the above solution won’t work. A better way to improve performances (and the look of the image) is to hard-code a colormap in an array and to use it when needed:
Collapse | Copy Code float pp_step = 2.0f / (float)COLOR_NUM;
unsigned char m_colorMap[COLOR_NUM][3] =
{
{0,0,143},{0,0,159},{0,0,175},{0,0,191},{0,0,207},{0,0,223},{0,0,239},{0,0,255},
{0,16,255},{0,32,255},{0,48,255},{0,64,255},{0,80,255},{0,96,255},{0,111,255},{0,128,255},
{0,143,255},{0,159,255},{0,175,255},{0,191,255},{0,207,255},{0,223,255},{0,239,255},{0,255,255},
{16,255,239},{32,255,223},{48,255,207},{64,255,191},{80,255,175},{96,255,159},{111,255,143},{128,255,128},
{143,255,111},{159,255,96},{175,255,80},{191,255,64},{207,255,48},{223,255,32},{239,255,16},{255,255,0},
{255,239,0},{255,223,0},{255,207,0},{255,191,0},{255,175,0},{255,159,0},{255,143,0},{255,128,0},
{255,111,0},{255,96,0},{255,80,0},{255,64,0},{255,48,0},{255,32,0},{255,16,0},{255,0,0},
{239,0,0},{223,0,0},{207,0,0},{191,0,0},{175,0,0},{159,0,0},{143,0,0},{128,0,0},
{100,0,20},{80,0,40},{60,0,60},{40,0,80},{20,0,100},{0,0,120}
};
RGB getColorFromValue(float value)
{
RGB result;
unsigned int cvalue = (unsigned int)((value + 1.0f)/pp_step);
if(cvalue < 0)
cvalue = 0;
else if(cvalue >= COLOR_NUM)
cvalue = COLOR_NUM-1;
result.r = m_colorMap[cvalue][0];
result.g = m_colorMap[cvalue][1];
result.b = m_colorMap[cvalue][2];
return result;
}
Creating a colormap isn’t hard and different colormaps are freely available on the web which produce different transition effects. This time the result was much nicer (see the screenshot later on) and the performances (although an every-value conversion is always an intensive task) increased substantially.
The last part involved in the on-screen rendering is adding a droplet wherever the user clicks on the window with the cursor. One droplet is automatically added at the center of the surface (you can find the code in the kernel() function, it is controlled by the first_droplet variable) but the user can click everywhere (almost everywhere) on the surface to add another droplet in that spot. To achieve this a queue has been implemented to contain at the most 60 droplet centers where the Gaussian matrix will be placed (notice that the matrix will be added to the surface values that were already present in the spots, not just replace them).
Collapse | Copy Code #define MAX_DROPLET 60
typedef struct Droplet
{
int mx;
int my;
} Droplet;
Droplet dropletQueue[MAX_DROPLET];
int dropletQueueCount = 0;
The queue system has been implemented for a reason: unlike the algorithm in pseudo-code we wrote before, rendering a scene with openGL requires the program to control the objects to be displayed in immediate-mode: that means the program needs to take care of what should be drawn before the actual rendering is performed, it cannot simply put a droplet to be rendered inside the data to be drawn because it could be in use (you can do this in retained-mode). Besides, we don’t know when a droplet will be added because it’s totally user-dependent. Because of that, every time the kernel() finishes, the droplet queue is emptied and the droplet Gaussian matrices are added to the data to be rendered (the surface data). The code which performs this is the following
Collapse | Copy Code void openGLRenderer::renderWaitingDroplets()
{
while(dropletQueueCount > 0)
{
dropletQueueCount--;
addDroplet(dropletQueue[dropletQueueCount].mx,dropletQueue[dropletQueueCount].my);
}
}
void addDroplet( int x0d, int y0d )
{
y0d = DIM - y0d;
for(int Zdi=0; Zdi< m_simulationData.Ddim; Zdi++)
{
for(int Zdj=0; Zdj< m_simulationData.Ddim; Zdj++)
{
(*m_simulationData.u)(y0d-2*m_simulationData.dsz+Zdi,x0d-2*m_simulationData.dsz+Zdj)
+= (*m_simulationData.Zd)(Zdi, Zdj);
}
}
}
The code should be familiar by now: the addDroplet function simply adds the Zd 2D Gaussian matrix to the simulation data (the kernel data) at the “current” time, a.k.a. the u matrix which represents the surface.
The code loops until the keyboard callback handler (defined by the openGLrenderer) detects the Esc keypress, after that the application is issued a termination signal, the loops ends. The resources allocated by the program are freed before the exit signal is issued, however this might not be necessary since a program termination would let the OS free any of its previously allocated resources.
With the droplet-adding feature and all the handlers set the code is ready to run. This time the result is much nicer than the previous, that’s because we used a smoother colormap (take a look at the images below). Notice how the convolution term creates the “wave spreading” and the “bouncing” effect when computing values against the padded zero data outside the surface matrix (i.e. when the wave hits the window’s borders and is reflected back). The first image is the simulation in its early stage, that is when some droplets have just been added, the second image represents a later stage when the surface is going to calm down (in our colormap blue values are higher than red ones).


Since we introduced a damping factor (recall it from the theory section), the waves are eventually going to cease and the surface will sooner or later be quiet again. The entire simulation is (except for the colors) quite realistic but quite slow too. That’s because the entire surface matrix is being thoroughly updated and calculated by the system. The kernel() function runs continuously updating the rendering buffer. For a 512x512 image the CPU has to process a large quantity of data and it has also to perform 512x512 floating point convolutions. Using a profiler (like VS’s integrated one) shows that the program spends most of its time in the kernel() call (as we expected) and that the convolution operation is the most cpu-intensive.

It is also interesting to notice that the simulation speed decreases substantially when adding lots of droplets.
In a real scientific simulation environment gigantic quantities of data need to be processed in relatively small time intervals. That’s where GPGPU computing comes into the scene. We will briefly summarize what this acronym means and then we will present a GPU-accelerated version of the wave PDE simulation.

GPGPU stands for General Purpose computation on Graphics Processing Units and indicates using graphic processors and devices to perform high parallelizable computations that would normally be handled by CPU devices. The idea of using graphic devices to help CPUnits with their workloads isn’t new, but until recent architectures and frameworks like CUDA (©NVIDIA vendor-specific) or openCL showed up, programmers had to rely on series of workarounds and tricks to work with inconvenient and unintuitive methods and data structures. The reason why a developer should think about porting his CPU-native code into a new GPU version resides in the architecture design differences between CPUs and GPUs. While CPUs evolved (multicore) to gain performance advantages with sequential executions (pipelines, caches, control flows, etc..), GPUs evolved in a many-core way: they tended to operate at higher data bandwidths and chose to heavily increase their execution threads number. In the last years GPGPU has been seen as a new opportunity to use graphical processing units as algebraic coprocessors capable of handling massive parallelization and precision floating point calculations. The idea behind GPGPU architectures is letting CPU handling sequential parts of programs and GPU getting over with parallelizable parts. In fact many scientific applications and systems found their performances increased by such an approach and GPGPU is now a fundamental technology in many fields like medical imaging, physics simulations, signal processing, cryptography, intrusion detection, environmental sciences, etc..
We chose to use the CUD-Architecture to parallelize some parts of our code. Parallelizing with GPGPU techniques means passing from a sequentially-designed code to a parallel-designed code, this also often means having to rewrite large parts of your code. The most obvious part of the entire simulation algorithm that could benefit of a parallel approach is the surface matrix convolution with the 2D Laplacian kernel.
Notice: for brevity’s sake, we will assume that the reader is already familiar with CUDA C/C++.
The CUDA SDK comes with a large variety of examples regarding how to implement an efficient convolution between matrices and how to apply a kernel as an image filter. However we decided to implement our own version rather than rely on standard techniques. The reasons are many:
- we wanted to show how a massively parallel algorithm is designed and implemented
- since our kernel is very small (3x3 2D Laplacian kernel, basically 9 float values) using a FFT approach like the one described by Victor Podlozhnyuk would be inefficient
- the two-dimensional Gaussian kernel is the only radially symmetric function that is also separable, our kernel is not, so we cannot use separable convolution methods
- such a small kernel seems perfect to be “aggressively cached” in the convolution operation. We’ll expand on that as soon as we describe the CUDA kernel designed
The most obvious way to perform a convolution (although extremely inefficient) consists in delegating each GPU thread multiple convolutions for each element across the entire image.
Take a look at the following image, we will use a 9x9 thread grid (just one block to simplify things) to perform the convolution. The purple square is our 9x9 grid while the red grids correspond to the 9x9 kernel. Each thread performs the convolution within its elements, then the X are shifted and the entire block is “virtually” moved to the right. When the X coordinate is complete (that is: the entire image horizontal area has been covered), the Y coordinate is incremented and the process starts again until completion. In the border area, every value outside the image will be set to zero.
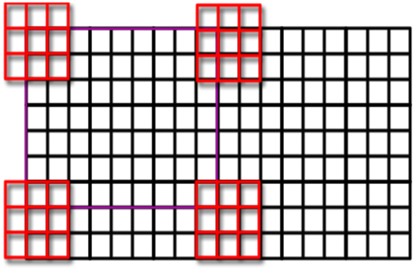
The code for this simple approach is the following where A is the image matrix and B is the kernel.
Collapse | Copy Code __global__ void convolutionGPU(float *A, int A_cols, int A_rows, float *B, int B_Wradius, int B_Hradius,
int B_cols, int B_rows, float *result)
{
int threadXabs = blockIdx.x*blockDim.x + threadIdx.x;
int threadYabs = blockIdx.y*blockDim.y + threadIdx.y;
int threadXabsInitialPos = threadXabs;
float convSum;
while(threadYabs < A_rows)
{
while(threadXabs < A_cols)
{
convSum = 0.0f;
#pragma unroll
for(int xrel=-B_Wradius;xrel<(B_Wradius+1); xrel++)
{
#pragma unroll
for(int yrel=-B_Hradius;yrel<(B_Hradius+1); yrel++)
{
float Avalue;
if(threadXabs + xrel < 0 || threadYabs + yrel <0 || threadXabs + xrel >= A_cols || threadYabs + yrel >= A_rows)
Avalue = 0;
else
Avalue = A[ (threadYabs+yrel)*A_cols + (threadXabs + xrel) ];
float Bvalue = B[ (yrel+B_Hradius)*B_cols + (xrel+B_Wradius) ];
convSum += Avalue * Bvalue;
}
}
result[threadYabs*A_cols + threadXabs ] = convSum;
threadXabs += blockDim.x * gridDim.x;
}
threadXabs = threadXabsInitialPos;
threadYabs += blockDim.y * gridDim.y;
}
}
As already stated, this simple approach has several disadvantages
- The kernel is very small, keeping it into global memory and accessing to it for every convolution performed is extremely inefficient
- Although the matrix readings are partially coalesced, thread divergence can be significant with threads active in the border area and threads that are inactive
- There’s no collaborative behavior among threads, although they basically use the same kernel and share a large part of the apron region
Hence a way better method to perform GPU convolution has been designed keeping in mind the points above.
The idea is simple: letting each thread load part of the apron and data regions in the shared memory thus maximizing readings coalescence and reducing divergence.
The code that performs the convolution on the GPU version of the simulation is the following
Collapse | Copy Code __global__ void convolutionGPU(float *A, float *result)
{
__shared__ float data[laplacianD*2][laplacianD*2];
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
const int x0 = threadIdx.x + IMUL(blockIdx.x,blockDim.x);
const int y0 = threadIdx.y + IMUL(blockIdx.y,blockDim.y);
int x,y;
x = x0 - kernelRadius;
y = y0 - kernelRadius;
if(x < 0 || y < 0)
data[threadIdx.x][threadIdx.y] = 0.0f;
else
data[threadIdx.x][threadIdx.y] = A[ gLoc - kernelRadius - IMUL(DIM,kernelRadius)];
x = x0 + kernelRadius + 1;
y = y0 - kernelRadius;
if(x >= DIM || y < 0)
data[threadIdx.x + blockDim.x][threadIdx.y] = 0.0f;
else
data[threadIdx.x + blockDim.x][threadIdx.y] = A[ gLoc + kernelRadius+1 - IMUL(DIM,kernelRadius)];
x = x0 - kernelRadius;
y = y0 + kernelRadius+1;
if(x < 0 || y >= DIM)
data[threadIdx.x][threadIdx.y + blockDim.y] = 0.0f;
else
data[threadIdx.x][threadIdx.y + blockDim.y] = A[ gLoc - kernelRadius + IMUL(DIM,(kernelRadius+1))];
x = x0 + kernelRadius+1;
y = y0 + kernelRadius+1;
if(x >= DIM || y >= DIM)
data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = 0.0f;
else
data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = A[ gLoc + kernelRadius+1 + IMUL(DIM,(kernelRadius+1))];
__syncthreads();
float sum = 0;
x = kernelRadius + threadIdx.x;
y = kernelRadius + threadIdx.y;
#pragma unroll
for(int i = -kernelRadius; i<=kernelRadius; i++)
for(int j=-kernelRadius; j<=kernelRadius; j++)
sum += data[x+i][y+j] * gpu_D[i+kernelRadius][j+kernelRadius];
result[gLoc] = sum;
}
The kernel only receives the surface matrix and the result where to store the convolved image. The kernel isn’t provided because it has been put into a special memory called “constant memory” which is read-only by kernels, pre-fetched and highly optimized to let all threads read from a specific location with minimum latency. The downside is that this kind of memory is extremely limited (in the order of 64Kb) so should be used wisely. Declaring our 3x3 kernel as constant memory grants us a significant speed advantage
__device__ __constant__ float gpu_D[laplacianD][laplacianD]; // Laplacian 2D kernel
The image below helps to determine how threads load from the surface matrix in the global memory the data and store them into faster on-chip shared memory before actually using them in the convolution operation. The purple 3x3 square is the kernel window and the central element is the value we are actually pivoting on. The grid is a 172x172 blocks 3x3 threads each one; each block of 3x3 threads have four stages to complete before entering the convolution loop: load the upper left apron and image data into shared memory (the upper left red square from the kernel purple window), load the upper right area (red square), load the lower left area (red square) and load the lower right area (idem). Since shared memory is only available to the threads in a block, each block loads its own shared area. Notice that we chose to let every thread read something from global memory to maximize coalescence, but we are not actually going to use every single element. The image shows a yellow area and a gray area: the yellow data is actually going to be used in the convolution operation for each element in the purple kernel square (it comprises aprons and data) while the gray area isn’t going to be used by any convolution performed by the block we are considering.
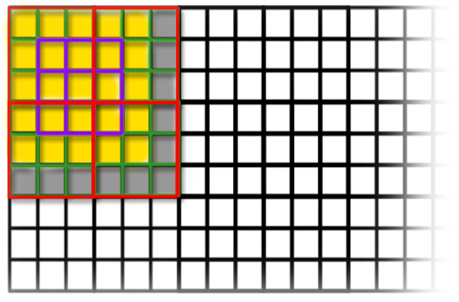
After filling each block’s shared memory array, the CUDA threads get synchronized to minimize their divergence. Then the execution of the convolution algorithm is performed: shared data is multiplied against constant kernel data resulting in a highly optimized operation.
The #pragma unroll directive instructs the compiler to unroll (where possible) the loop to reduce cycle control overhead and improve performances. A small example of loop unrolling: the following loop
for(int i=0;i<1000;i++)
a[i] = b[i] + c[i];
might be optimized by unrolling it
for(int i=0;i<1000;i+=2)
{
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}
so that the control instructions are executed less and the overall loop improves its performances. It is to be noticed that almost every optimization in CUDA code needs to be carefully and thoroughly tested because a different architecture and different program control flows might produce different results (as well as different compiler optimizations that, unfortunately, cannot be always trusted).
Also notice that the IMUL macro is used in the code which is defined as
#define IMUL(a,b) __mul24(a,b)
On devices of CUDA compute capability 1.x, 32-bit integer multiplication is implemented using multiple instructions as it is not natively supported. 24-bit integer multiplication is natively supported via the __[u]mul24 intrinsic. However on devices of compute capability 2.0, however, 32-bit integer multiplication is natively supported, but 24-bit integer multiplication is not. __[u]mul24 is therefore implemented using multiple instructions and should not be used. So if you are planning to use the code on 2.x devices, make sure to redefine the macro directive.
A typical code which could call the kernel we just wrote could be
Collapse | Copy Code sMatrix convolutionGPU_i(sMatrix& A, sMatrix& B)
{
unsigned int A_bytes = A.rows*A.columns*sizeof(float);
sMatrix result(A.rows, A.columns);
float *cpu_result = (float*)malloc(A_bytes);
cudaError_t chk;
chk = cudaMemcpy(m_gpuData->gpu_matrixA, A.values, A_bytes, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT TRANSFER MEMORY TO GPU");
return result;
}
dim3 blocks(172,172);
dim3 threads(3,3);
convolutionGPU<<<blocks,threads>>>(m_gpuData->gpu_matrixA, m_gpuData->gpu_matrixResult);
chk = cudaMemcpy(cpu_result, m_gpuData->gpu_matrixResult, A_bytes, cudaMemcpyDeviceToHost);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT TRANSFER MEMORY FROM GPU");
return result;
}
free(result.values);
result.values = cpu_result;
return result;
}
obviously CUDA memory should be cudaMalloc-ated at the beginning of our program and freed only when the GPU work is complete.
However, as we stated before, converting a sequentially-designed program into a parallel one isn’t an easy task and often requires more than just a plain function-to-function conversion (it depends on the application). In our case substituting just a CPU-convolution function with a GPU-convolution function won’t work. In fact even though we distributed our workload in a better way from the CPU version (see the images below for a CPU-GPU exclusive time percentage), we actually slowed down the whole simulation.


The reason is simple: our kernel() function is called whenever a draw event is dispatched, so it needs to be called very often. Although the CUDA kernel is faster than the CPU convolution function and although GPU memory bandwidths are higher than CPU’s, transferring from (possibly paged-out) host memory to global device memory back and forth just kills our simulation performances. Applications which would benefit more from a CUDA approach usually perform a single-shot heavily-computational kernel workload and then transfer back the results. Real time applications might benefit from a concurrent kernels approach, but a 2.x capability device would be required.
In order to actually accelerate our simulation, a greater code revision is required.
Another more subtle thing to take into account when working with GPU code is CPU optimizations: take a look at the following asm codes for the CPU version of the line
un = (*data.u)*data.a1 + (*data.u0)*data.a2 + convolutionCPU((*data.u),(*data.D))*data.c1;
Collapse | Copy Code 000000013F2321EF mov r8,qword ptr [m_simulationData+20h (13F234920h)]
000000013F2321F6 mov rdx,qword ptr [m_simulationData+10h (13F234910h)]
000000013F2321FD lea rcx,[rbp+2Fh]
000000013F232201 call convolutionCPU (13F231EC0h)
000000013F232206 nop
000000013F232207 movss xmm2,dword ptr [m_simulationData+8 (13F234908h)]
000000013F23220F lea rdx,[rbp+1Fh]
000000013F232213 mov rcx,rax
000000013F232216 call sMatrix::operator* (13F2314E0h)
000000013F23221B mov rdi,rax
000000013F23221E movss xmm2,dword ptr [m_simulationData+4 (13F234904h)]
000000013F232226 lea rdx,[rbp+0Fh]
000000013F23222A mov rcx,qword ptr [m_simulationData+18h (13F234918h)]
000000013F232231 call sMatrix::operator* (13F2314E0h)
000000013F232236 mov rbx,rax
000000013F232239 movss xmm2,dword ptr [m_simulationData (13F234900h)]
000000013F232241 lea rdx,[rbp-1]
000000013F232245 mov rcx,qword ptr [m_simulationData+10h (13F234910h)]
000000013F23224C call sMatrix::operator* (13F2314E0h)
000000013F232251 nop
000000013F232252 mov r8,rbx
000000013F232255 lea rdx,[rbp-11h]
000000013F232259 mov rcx,rax
000000013F23225C call sMatrix::operator+ (13F2315B0h)
000000013F232261 nop
000000013F232262 mov r8,rdi
000000013F232265 lea rdx,[rbp-21h]
000000013F232269 mov rcx,rax
000000013F23226C call sMatrix::operator+ (13F2315B0h)
000000013F232271 nop
000000013F232272 cmp dword ptr [rax],1F4h
000000013F232278 jne kernel+33Fh (13F2324CFh)
000000013F23227E cmp dword ptr [rax+4],1F4h
000000013F232285 jne kernel+33Fh (13F2324CFh)
000000013F23228B mov r8d,0F4240h
000000013F232291 mov rdx,qword ptr [rax+8]
000000013F232295 mov rcx,r12
000000013F232298 call memcpy (13F232DDEh)
000000013F23229D nop
000000013F23229E mov rcx,qword ptr [rbp-19h]
000000013F2322A2 call qword ptr [__imp_operator delete (13F233090h)]
000000013F2322A8 nop
000000013F2322A9 mov rcx,qword ptr [rbp-9]
000000013F2322AD call qword ptr [__imp_operator delete (13F233090h)]
000000013F2322B3 nop
000000013F2322B4 mov rcx,qword ptr [rbp+7]
000000013F2322B8 call qword ptr [__imp_operator delete (13F233090h)]
000000013F2322BE nop
000000013F2322BF mov rcx,qword ptr [rbp+17h]
000000013F2322C3 call qword ptr [__imp_operator delete (13F233090h)]
000000013F2322C9 nop
000000013F2322CA mov rcx,qword ptr [rbp+27h]
000000013F2322CE call qword ptr [__imp_operator delete (13F233090h)]
000000013F2322D4 nop
000000013F2322D5 mov rcx,qword ptr [rbp+37h]
000000013F2322D9 call qword ptr [__imp_operator delete (13F233090h)]
and now take a look at the GPU version of the line
un = (*data.u)*data.a1 + (*data.u0)*data.a2 + convolutionGPU_i ((*data.u),(*data.D))*data.c1;
Collapse | Copy Code 000000013F7E23A3 mov rax,qword ptr [data]
000000013F7E23AB movss xmm0,dword ptr [rax+8]
000000013F7E23B0 movss dword ptr [rsp+0A8h],xmm0
000000013F7E23B9 mov rax,qword ptr [data]
000000013F7E23C1 mov r8,qword ptr [rax+20h]
000000013F7E23C5 mov rax,qword ptr [data]
000000013F7E23CD mov rdx,qword ptr [rax+10h]
000000013F7E23D1 lea rcx,[rsp+70h]
000000013F7E23D6 call convolutionGPU_i (13F7E1F20h)
000000013F7E23DB mov qword ptr [rsp+0B0h],rax
000000013F7E23E3 mov rax,qword ptr [rsp+0B0h]
000000013F7E23EB mov qword ptr [rsp+0B8h],rax
000000013F7E23F3 movss xmm0,dword ptr [rsp+0A8h]
000000013F7E23FC movaps xmm2,xmm0
000000013F7E23FF lea rdx,[rsp+80h]
000000013F7E2407 mov rcx,qword ptr [rsp+0B8h]
000000013F7E240F call sMatrix::operator* (13F7E2B20h)
000000013F7E2414 mov qword ptr [rsp+0C0h],rax
000000013F7E241C mov rax,qword ptr [rsp+0C0h]
000000013F7E2424 mov qword ptr [rsp+0C8h],rax
000000013F7E242C mov rax,qword ptr [data]
000000013F7E2434 movss xmm0,dword ptr [rax+4]
000000013F7E2439 movaps xmm2,xmm0
000000013F7E243C lea rdx,[rsp+50h]
000000013F7E2441 mov rax,qword ptr [data]
000000013F7E2449 mov rcx,qword ptr [rax+18h]
000000013F7E244D call sMatrix::operator* (13F7E2B20h)
000000013F7E2452 mov qword ptr [rsp+0D0h],rax
000000013F7E245A mov rax,qword ptr [rsp+0D0h]
000000013F7E2462 mov qword ptr [rsp+0D8h],rax
000000013F7E246A mov rax,qword ptr [data]
000000013F7E2472 movss xmm2,dword ptr [rax]
000000013F7E2476 lea rdx,[rsp+40h]
000000013F7E247B mov rax,qword ptr [data]
000000013F7E2483 mov rcx,qword ptr [rax+10h]
000000013F7E2487 call sMatrix::operator* (13F7E2B20h)
000000013F7E248C mov qword ptr [rsp+0E0h],rax
000000013F7E2494 mov rax,qword ptr [rsp+0E0h]
000000013F7E249C mov qword ptr [rsp+0E8h],rax
000000013F7E24A4 mov r8,qword ptr [rsp+0D8h]
000000013F7E24AC lea rdx,[rsp+60h]
000000013F7E24B1 mov rcx,qword ptr [rsp+0E8h]
000000013F7E24B9 call sMatrix::operator+ (13F7E2BF0h)
000000013F7E24BE mov qword ptr [rsp+0F0h],rax
000000013F7E24C6 mov rax,qword ptr [rsp+0F0h]
000000013F7E24CE mov qword ptr [rsp+0F8h],rax
000000013F7E24D6 mov r8,qword ptr [rsp+0C8h]
000000013F7E24DE lea rdx,[rsp+90h]
000000013F7E24E6 mov rcx,qword ptr [rsp+0F8h]
000000013F7E24EE call sMatrix::operator+ (13F7E2BF0h)
000000013F7E24F3 mov qword ptr [rsp+100h],rax
000000013F7E24FB mov rax,qword ptr [rsp+100h]
000000013F7E2503 mov qword ptr [rsp+108h],rax
000000013F7E250B mov rdx,qword ptr [rsp+108h]
000000013F7E2513 lea rcx,[un]
000000013F7E2518 call sMatrix::operator= (13F7E2A90h)
000000013F7E251D nop
000000013F7E251E lea rcx,[rsp+90h]
000000013F7E2526 call sMatrix::~sMatrix (13F7E2970h)
000000013F7E252B nop
000000013F7E252C lea rcx,[rsp+60h]
000000013F7E2531 call sMatrix::~sMatrix (13F7E2970h)
000000013F7E2536 nop
000000013F7E2537 lea rcx,[rsp+40h]
000000013F7E253C call sMatrix::~sMatrix (13F7E2970h)
000000013F7E2541 nop
000000013F7E2542 lea rcx,[rsp+50h]
000000013F7E2547 call sMatrix::~sMatrix (13F7E2970h)
000000013F7E254C nop
000000013F7E254D lea rcx,[rsp+80h]
000000013F7E2555 call sMatrix::~sMatrix (13F7E2970h)
000000013F7E255A nop
000000013F7E255B lea rcx,[rsp+70h]
000000013F7E2560 call sMatrix::~sMatrix(13F7E2970h)
the code, although the data involved are practically the same, looks much more bloated up (there are even nonsense operations, look at address 000000013F7E23DB). Probably letting the CPU finish the calculation after the GPU has done its work is not a good idea.
Since there are other functions which can be parallelized (like the matrix2bitmap() function), we need to move as much workload as possible on the device.
First we need to allocate memory on the device at the beginning of the program and deallocate it when finished. Small data like our algorithm parameters can be stored into constant memory to boost performances, while matrices large data is more suited into global memory (constant memory size is very limited).
Collapse | Copy Code void initializeGPUData()
{
float dt = (float)0.05;
float c = 1;
float dx = 1;
float k = (float)0.002;
float da = (float)0.07;
sMatrix u0(DIM,DIM);
for(int i=0; i<DIM; i++)
{
for(int j=0; j<DIM; j++)
{
u0(i,j) = 0.0f; }
}
CPUsMatrix2Bitmap(u0, renderImg);
float kdt=k*dt;
float c1=pow(dt,2)*pow(c,2)/pow(dx,2);
const int dim = 4*dropletRadius+1;
sMatrix xd(dim, dim);
sMatrix yd(dim, dim);
for(int i=0; i<dim; i++)
{
for(int j=-2*dropletRadius; j<=2*dropletRadius; j++)
{
xd(i,j+2*dropletRadius) = j;
yd(j+2*dropletRadius,i) = j;
}
}
float m_Zd[dim][dim];
for(int i=0; i<dim; i++)
{
for(int j=0; j<dim; j++)
{
m_Zd[i][j] = -da*exp(-pow(xd(i,j)/dropletRadius,2)-pow(yd(i,j)/dropletRadius,2));
}
}
unsigned int UU0_bytes = DIM*DIM*sizeof(float);
cudaError_t chk;
chk = cudaMalloc((void**)&m_gpuData.gpu_u, UU0_bytes);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMalloc((void**)&m_gpuData.gpu_u0, UU0_bytes);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMalloc((void**)&m_gpuData.ris0, UU0_bytes);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMalloc((void**)&m_gpuData.ris1, UU0_bytes);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMalloc((void**)&m_gpuData.ris2, UU0_bytes);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMalloc((void**)&m_gpuData.gpu_ptr, DIM*DIM*4);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE GPU MEMORY");
return;
}
chk = cudaMemcpy(m_gpuData.gpu_u0, u0.values, UU0_bytes, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT TRANSFER MEMORY TO GPU");
return;
}
chk = cudaMemcpy(m_gpuData.gpu_u, u0.values, UU0_bytes, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT TRANSFER MEMORY TO GPU");
return;
}
float m_D[3][3];
m_D[0][0] = 0.0f; m_D[1][0] = 1.0f; m_D[2][0]=0.0f;
m_D[0][1] = 1.0f; m_D[1][1] = -4.0f; m_D[2][1]=1.0f;
m_D[0][2] = 0.0f; m_D[1][2] = 1.0f; m_D[2][2]=0.0f;
chk = cudaMemcpyToSymbol((const char*)gpu_D, m_D, 9*sizeof(float), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
const float a1 = (2-kdt);
chk = cudaMemcpyToSymbol((const char*)&gpu_a1, &a1, sizeof(float), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
const float a2 = (kdt-1);
chk = cudaMemcpyToSymbol((const char*)&gpu_a2, &a2, sizeof(float), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
chk = cudaMemcpyToSymbol((const char*)&gpu_c1, &c1, sizeof(float), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
const int ddim = dim;
chk = cudaMemcpyToSymbol((const char*)&gpu_Ddim, &ddim, sizeof(int), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
const int droplet_dsz = dropletRadius;
chk = cudaMemcpyToSymbol((const char*)&gpu_dsz, &droplet_dsz, sizeof(int), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
chk = cudaMemcpyToSymbol((constchar*)&gpu_Zd, &m_Zd, sizeof(float)*dim*dim, 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
chk = cudaMemcpyToSymbol((const char*)&gpu_pp_step, &pp_step, sizeof(float), 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
chk = cudaMemcpyToSymbol((const char*)&gpu_m_colorMap, &m_colorMap, sizeof(unsigned char)*COLOR_NUM*3, 0, cudaMemcpyHostToDevice);
if(chk != cudaSuccess)
{
printf("\nCONSTANT MEMORY TRANSFER FAILED");
return;
}
}
void deinitializeGPUData()
{
cudaFree(m_gpuData.gpu_u);
cudaFree(m_gpuData.gpu_u0);
cudaFree(m_gpuData.gpu_ptr);
cudaFree(m_gpuData.ris0);
cudaFree(m_gpuData.ris1);
cudaFree(m_gpuData.ris2);
}
After initializing the GPU memory the openGLRenderer can be started as usual to call the kernel() function in order to obtain a valid render-able surface image matrix. But there’s a difference now, right in the openGLRenderer constructor
Collapse | Copy Code openGLRenderer::openGLRenderer(void)
{
cublasStatus_t status = cublasInit();
if (status != CUBLAS_STATUS_SUCCESS)
{
printf("\nCRITICAL: CUBLAS LIBRARY FAILED TO LOAD");
return;
}
cudaError_t chk = cudaHostAlloc((void**)&renderImg, DIM*DIM*4*sizeof(char), cudaHostAllocDefault);
if(chk != cudaSuccess)
{
printf("\nCRITICAL: CANNOT ALLOCATE PAGELOCKED MEMORY");
return ;
}
}
First we decided to use CUBLAS library to perform matrix addition for two reasons:
- our row-major data on the device is ready to be used by the CUBLAS functions yet (cublasMalloc is just a wrapper around the cudaMalloc)
- CUBLAS library is extremely optimized for large matrices operations; our matrices aren’t that big but this could help extending the architecture for a future version
Using our sMatrix wrapper is no more an efficient choice and we need to get rid of it while working on the device, although we can still use it for the initialization stage.
The second fundamental thing that we need to notice in the openGLRenderer constructor is that we allocated host-side memory (the memory that will contain the data to be rendered) with cudaHostAlloc instead of the classic malloc. As the documentation states, allocating memory with such a function grants that the CUDA driver will track the virtual memory ranges allocated with this function and accelerate calls to function like cudaMemCpy. Host memory allocated with cudaHostAlloc is often referred as “pinned memory”, and cannot be paged-out (and because of that allocating excessive amounts of it may degrade system performance since it reduces the amount of memory available to the system for paging). This expedient will grant additional speed in memory transfers between device and host.
We are not ready to take a peek at the revised kernel() function
Collapse | Copy Code void kernel(unsigned char *ptr)
{
dim3 blocks(172,172);
dim3 threads(3,3);
convolutionGPU<<<blocks,threads>>>(m_gpuData.gpu_u, m_gpuData.ris0);
multiplyEachElementby_c1<<<blocks,threads>>>(m_gpuData.ris0, m_gpuData.ris1);
multiplyEachElementby_a1<<<blocks,threads>>>(m_gpuData.gpu_u, m_gpuData.ris0);
multiplyEachElementby_a2<<<blocks,threads>>>(m_gpuData.gpu_u0, m_gpuData.ris2);
cublasSaxpy(DIM*DIM, 1.0f, m_gpuData.ris0, 1, m_gpuData.ris2, 1);
cublasSaxpy(DIM*DIM, 1.0f, m_gpuData.ris2, 1, m_gpuData.ris1, 1);
cudaMemcpy(m_gpuData.gpu_u0, m_gpuData.gpu_u, DIM*DIM*sizeof(float), cudaMemcpyDeviceToDevice);
cudaMemcpy(m_gpuData.gpu_u, m_gpuData.ris1, DIM*DIM*sizeof(float), cudaMemcpyDeviceToDevice);
gpuMatrix2Bitmap<<<blocks,threads>>>(m_gpuData.gpu_u, m_gpuData.gpu_ptr);
cudaMemcpy(ptr, m_gpuData.gpu_ptr, DIM*DIM*4, cudaMemcpyDeviceToHost);
if(first_droplet == 1) {
first_droplet = 0;
int x0d= DIM / 2; int y0d= DIM / 2;
cudaMemcpy(m_gpuData.ris0, m_gpuData.gpu_u, DIM*DIM*sizeof(float), cudaMemcpyDeviceToDevice);
addDropletToU<<<blocks,threads>>>(m_gpuData.ris0, x0d,y0d, m_gpuData.gpu_u);
}
while(dropletQueueCount >0)
{
dropletQueueCount--;
int y0d = DIM - dropletQueue[dropletQueueCount].my;
cudaMemcpy(m_gpuData.ris0, m_gpuData.gpu_u, DIM*DIM*sizeof(float), cudaMemcpyDeviceToDevice);
addDropletToU<<<blocks,threads>>>(m_gpuData.ris0, dropletQueue[dropletQueueCount].mx,y0d, m_gpuData.gpu_u);
}
cudaThreadSynchronize();
}
The line
un = (*data.u)*data.a1 + (*data.u0)*data.a2 + convolution((*data.u),(*data.D))*data.c1;
has completely been superseded by multiple kernel calls which respectively operate a convolution operation, multiply matrix data by algorithm constants and perform a matrix-matrix addition via CUBLAS. Everything is performed in the device including the point-to-RGBvalue mapping (which is a highly parallelizable operation since must be performed for every value in the surface image matrix). Stepping forward in time is also accomplished with device methods. Eventually the data is copied back to the page-locked pinned host memory and droplets waiting in the queue are added for the next iteration to the u surface simulation data matrix.
The CUDA kernels called by the kernel() function are the following
Collapse | Copy Code
__global__ void convolutionGPU(float *A, float *result)
{
__shared__ float data[laplacianD*2][laplacianD*2];
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
const int x0 = threadIdx.x + IMUL(blockIdx.x,blockDim.x);
const int y0 = threadIdx.y + IMUL(blockIdx.y,blockDim.y);
int x,y;
x = x0 - kernelRadius;
y = y0 - kernelRadius;
if(x < 0 || y < 0)
data[threadIdx.x][threadIdx.y] = 0.0f;
else
data[threadIdx.x][threadIdx.y] = A[ gLoc - kernelRadius - IMUL(DIM,kernelRadius)];
x = x0 + kernelRadius + 1;
y = y0 - kernelRadius;
if(x >= DIM || y < 0)
data[threadIdx.x + blockDim.x][threadIdx.y] = 0.0f;
else
data[threadIdx.x + blockDim.x][threadIdx.y] = A[ gLoc + kernelRadius+1 - IMUL(DIM,kernelRadius)];
x = x0 - kernelRadius;
y = y0 + kernelRadius+1;
if(x < 0 || y >= DIM)
data[threadIdx.x][threadIdx.y + blockDim.y] = 0.0f;
else
data[threadIdx.x][threadIdx.y + blockDim.y] = A[ gLoc - kernelRadius + IMUL(DIM,(kernelRadius+1))];
x = x0 + kernelRadius+1;
y = y0 + kernelRadius+1;
if(x >= DIM || y >= DIM)
data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = 0.0f;
else
data[threadIdx.x + blockDim.x][threadIdx.y + blockDim.y] = A[ gLoc + kernelRadius+1 + IMUL(DIM,(kernelRadius+1))];
__syncthreads();
float sum = 0;
x = kernelRadius + threadIdx.x;
y = kernelRadius + threadIdx.y;
#pragma unroll
for(int i = -kernelRadius; i<=kernelRadius; i++)
for(int j=-kernelRadius; j<=kernelRadius; j++)
sum += data[x+i][y+j] * gpu_D[i+kernelRadius][j+kernelRadius];
result[gLoc] = sum;
}
__global__ void multiplyEachElementby_c1(float *matrix, float *result)
{
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
result[gLoc] = matrix[gLoc]*gpu_c1;
}
__global__ void multiplyEachElementby_a1(float *matrix, float *result)
{
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
result[gLoc] = matrix[gLoc]*gpu_a1;
}
__global__ void multiplyEachElementby_a2(float *matrix, float *result)
{
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
result[gLoc] = matrix[gLoc]*gpu_a2;
}
__global__ void gpuMatrix2Bitmap(float *matrix, BYTE *bitmap)
{
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
int cvalue = (int)((matrix[gLoc] + 1.0f)/gpu_pp_step);
if(cvalue < 0)
cvalue = 0;
else if(cvalue >= COLOR_NUM)
cvalue = COLOR_NUM-1;
bitmap[gLoc*4] = gpu_m_colorMap[cvalue][0];
bitmap[gLoc*4 + 1] = gpu_m_colorMap[cvalue][1];
bitmap[gLoc*4 + 2] = gpu_m_colorMap[cvalue][2];
bitmap[gLoc*4 + 3] = 0xFF; }
__global__ void addDropletToU(float *matrix, int x0d, int y0d, float *result)
{
const int gLoc = threadIdx.x + IMUL(blockIdx.x,blockDim.x) + IMUL(threadIdx.y,DIM) + IMUL(blockIdx.y,blockDim.y)*DIM;
const int x0 = threadIdx.x + IMUL(blockIdx.x,blockDim.x);
const int y0 = threadIdx.y + IMUL(blockIdx.y,blockDim.y);
if (x0 >= x0d-gpu_dsz*2 && y0 >= y0d-gpu_dsz*2 && x0 <= x0d+gpu_dsz*2 && y0 <= y0d+gpu_dsz*2)
{
result[gLoc] = matrix[gLoc] + gpu_Zd[x0 -(x0d-gpu_dsz*2)][y0 - (y0d-gpu_dsz*2)];
}
else
result[gLoc] = matrix[gLoc]; }
Notice that we preferred to “hardcode” the constant values usages with different kernels rather than introducing divergence with a conditional branch. The only kernel that increases thread divergence is the addDropletToU since only a few threads are actually performing the Gaussian packet-starting routine (see the theoric algorithm described a few paragraphs ago), but this isn’t a problem due to its low calling frequency.
The timing measurements and performance comparisons have been performed on the following system
Intel 2 quad cpu Q9650 @ 3.00 Ghz
6 GB ram
64 bit OS
NVIDIA GeForce GTX 285 (1GB DDR3 @ 1476 Mhz, 240 CUDA cores)
The CUDA version we used to compile the projects is 4.2, if you have problems make sure to install the right version or change it as described in the readme file.
To benchmark the CUDA kernel execution we used the cudaEventCreate / cudaEventRecord / cudaEventSynchronize / cudaEventElapsedTime functions shipped with every CUDA version, while for the CPU version we used two Windows platform-dependent APIs: QueryPerformanceFrequency and QueryPerformanceCounter.
We split the benchmark into four stages: a startup stage where the only droplet in the image is the default one, a second stage when both the CPU and the GPU version stabilized themselves, a third one where we add 60-70 droplets to the rendering queue and a final one when the application is left running for 15-20 minutes. We saw that in every test the CPU performed worse than the GPU version which could rely on a large grid of threads ready to split up an upcoming significant workload and provide a fixed rendering time. On the other hand in the long term period, although the GPU still did better, the CPU version showed a small performance increment, perhaps thanks to the caching mechanisms.

Notice that an application operating on larger data would surely have taken a greater advantage from a massive parallelization approach. Our wave PDE simulation is quite simple indeed and did not require a significant workload thus reducing the performance gain that could have been achieved.
Once and for all: there’s not a general rule to convert a sequentially-designed algorithm to a parallel one and each case must be evaluated in its own context and architecture. Also using CUDA could provide a great advantage in scientific simulations, but one should not consider the GPU as a substitute of the CPU but rather as a algebraic coprocessor that can rely on massive data parallelization. Combining CPU sequential code parts with GPU parallel code parts is the key to succeed.
The last, but not the least, section of this paper provide a checklist of best-practices and errors to avoid when writing CUDA kernels in order to get the maximum from your GPU-accelerated application
- Minimize host <-> device transfers, especially device -> host transfers which are slower, also if that could mean running on the device kernels that would not have been slower on the CPU.
- Use pinned memory (pagelocked) on the host side to exploit bandwidth advantages. Be careful not to abuse it or you’ll slow your entire system down.
- cudaMemcpy is a blocking function, if possible use it asynchronously with pinned memory + a CUDA stream in order to overlap transfers with kernel executions.
- If your graphic card is integrated, zero-copy memory (that is: pinned memory allocated with cudaHostAllocMapped flag) always grants an advantage. If not, there is no certainty since the memory is not cached by the GPU.
- Always check your device compute capabilities (use cudaGetDeviceProperties), if < 2.0 you cannot use more than 512 threads per block (65535 blocks maximum).
- Check your graphic card specifications: when launching a AxB block grid kernel, each SM (streaming multiprocessor) can serve a part of them. If your card has a maximum of 1024 threads per SM you should size your blocks in order to fill as many of them as possible but not too many (otherwise you would get scheduling latencies). Every warp is usually 32 thread (although this is not a fixed value and is architecture dependent) and is the minimum scheduling unit on each SM (only one warp is executed at any time and all threads in a warp execute the same instruction - SIMD), so you should consider the following example: on a GT200 card you need to perform a matrix multiplication. Should you use 8x8, 16x16 or 32x32 threads per block?
For 8X8 blocks, we have 64 threads per block. Since each SM can take up to 1024 threads, there are 16 Blocks (1024/64). However, each SM can only take up to 8 blocks. Hence only 512 (64*8) threads will go into each SM -> SM execution resources are under-utilized; fewer wraps to schedule around long latency operations
For 16X16 blocks , we have 256 threads per Block. Since each SM can take up to 1024 threads, it can take up to 4 Blocks (1024/256) and the 8 blocks limit isn’t hit -> Full thread capacity in each SM and maximal number of warps for scheduling around long-latency operations (1024/32= 32 wraps).
For 32X32 blocks, we have 1024 threads per block -> Not even one can fit into an SM! (there’s a 512 threads per block limitation).
- Check the SM registers limit per block and divide them by the thread number: you’ll get the maximum register number you can use in a thread. Exceeding it by just one per thread will cause less warp to be scheduled and decreased performance.
- Check the shared memory per block and make sure you don’t exceed that value. Exceeding it will cause less warp to be scheduled and decreased performance.
- Always check the thread number to be inferior than the maximum threads value supported by your device.
- Use reduction and locality techniques wherever applicable.
- If possible, never split your kernel code into conditional branches (if-then-else), different paths would cause more executions for the same warp and the following overhead.
- Use reduction techniques with divergence minimization when possible (that is, try to perform a reduction with warps performing a coalesced reading per cycle as described in chapter 6 of Kirk and Hwu book)
- Coalescence is achieved by forcing hardware reading consecutive data. If each thread in a warp access consecutive memory coalescence is significantly increased (half of the threads in a warp should access global memory at the same time), that’s why with large matrices (row-major) reading by columns is better than rows readings. Coalescence can be increased with locality (i.e. threads cooperating in loading data needed by other threads); kernels should perform coalesced readings with locality purposes in order to maximize memory throughputs. Storing values into shared memory (when possible) is a good practice too.
- Make sure you don’t have unused threads/blocks, by design or because of your code. As said before graphic cards have limits like maximum threads on SM and maximum blocks per SM. Designing your grid without consulting your card specifications is highly discouraged.
- As stated before adding more registers than the card maximum registers limit is a recipe for performance loss. Anyway adding a register may also cause instructions to be added, that is: more time to parallelize transfers or to schedule warps and better performances. Again: there’s no general rule, you should abide by the best practises when designing your code and then experiment by yourself.
- Data prefetching means preloading data you don’t actually need at the moment to gain performance in a future operation (closely related to locality). Combining data prefetching in matrix tiles can solve many long-latency memory access problems.
- Unrolling loops is preferable when applicable (as if the loop is small). Ideally loop unrolling should be automatically done by the compiler, but checking to be sure of that is always a better choice.
- Reduce thread granularity with rectangular tiles (Chapter 6 Kirk and Hwu book) when working with matrices to avoid multiple row/columns readings from global memory by different blocks.
- Textures are cached memory, if used properly they are significantly faster than global memory, that is: texture are better suited for 2D spatial locality accesses (e.g. multidimensional arrays) and might perform better in some specific cases (again, this is a case-by-case rule).
- Try to mantain at least 25% of the overall registers occupied, otherwise access latency could not be hidden by other warps’ computations.
- The number of threads per block should always be a multiple of warp size to favor coalesced readings.
- Generally if a SM supports more than just one block, more than 64 threads per block should be used.
- The starting values to begin experimenting with kernel grids are between 128 and 256 threads per block.
- High latency problems might be solved by using more blocks with less threads instead of just one block with a lot of threads per SM. This is important expecially for kernels which often call __syncthreads().
- If the kernel fails, use cudaGetLastError() to check the error value, you might have used too many registers / too much shared or constant memory / too many threads.
- CUDA functions and hardware perform best with float data type. Its use is highly encouraged.
- Integer division and modulus (%) are expensive operators, replace them with bitwise operations whenever possible. If n is a power of 2,
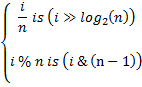
- Avoid automatic data conversion from double to float if possible.
- Mathematical functions with a __ preceeding them are hardware implemented, they’re faster but less accurate. Use them if precision is not a critical goal (e.g. __sinf(x) rather than sinf(x)).
- Use signed integers rather than unsigned integers in loops because some compilers optimize signed integers better (overflows with signed integers cause undefined behavior, then compilers might aggressively optimize them).
- Remember that floating point math is not associative because of round-off errors. Massively parallel results might differ because of this.
- 1) If your device supports concurrent kernel executions (see concurrentKernels device property) you might be able to gain additional performance by running kernels in parallel. Check your device specifications and the CUDA programming guides.
This concludes our article. The goal was an exploration of GPGPU applications capabilities to improve scientific simulations and programs which aim to large data manipulations.

